Subscribe to the mailing list for updates.
January 14, 2022
So, how fast is ECI really?
ECI is the Enzian Coherent Interconnect, our implementation of the cache coherence protocol that connects the XCVU9P FPGA on an Enzian board to the Marvell Cavium ThunderX-1 CPU.
Most of our use-cases for Enzian, and indeed our justification for building the thing in the first place, rely on this connection being fast, both high in bandwidth and low in latency. However, there are clearly limitations: with two 2.1GHz ThunderX-1 CPUs communicating in a 2-socket server (such as the Gigabyte R150-T51), you’re looking at two identical highly-tuned implementations. With Enzian, one of those is replaced by an FPGA running at around 300MHz.
That said, we’re proud of how fast it really is. Here are some recent micro-benchmark results from our upcoming ASPLOS paper:
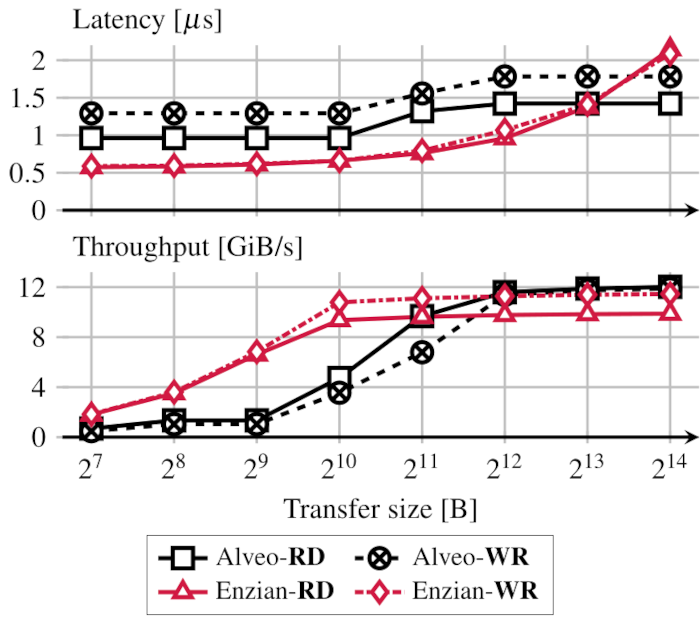
What’s happening here? This is a really low-level benchmark, designed to give us a baseline for achievable throughput and latency. The FPGA is issuing “uncached coherent” reads and writes to host memory on the ThunderX-1, initiating cache line transfers of 128 bytes each. It is also restricted to using only one of the two ECI links between the CPU and FPGA.
The comparison is with a Xilinx Alveo u250 card, doing the same thing over 16x PCIe Gen3 to an Intel Xeon server, which is a pretty respectable commercial implementation. The Alveo is doing large PCIe transfers, in contrast to Enzian issuing a series of essentially independent cache line requests.
We’re doing pretty well here: we’re significantly faster for transfers under 2KiB, and our latency is consistently better than a hardware PCIe implementation and a fast Intel server.
Not only that, using both ECI links would barely affect our latency, but increase the bandwidth well beyond that obtainable with PCIe setup, though (as we explain below) the details of doing this are tricky.
Note, however, that any non-trivial processing on the FPGA is therefore going to add more latency to these results, and is also likely to reduce the bandwidth (due to the way that response messages are packed into lower-level blocks in the ECI protocol).
Nonetheless, we still think this comfortably faster than any FPGA-based PCIe accelerator you can buy today - if it isn’t, please let us know!
How does this compare with 2 ThunderX-1 chips?
How fast can two ThunderX-1 chips communicate? After all, ECI is inter-operating with the ThunderX-1’s native protocol.
Fortunately, we can actually measure this. Thanks to Marvell, we have a couple of Gigabyte R150-T51 servers which have two sockets, and so we can run an equivalent benchmark going from cache-to-cache on these machines. This should give us an upper-bound on how fast ECI could be pushed - we’d be very surprised if an FPGA could beat two ThunderX-1’s running their native protocol.
We measured 19 GiB/s of bandwidth, and 150ns latency on this machine for cache-to-cache transfers.
Unsurprisingly, even though we’re faster than PCIe, we’re nowhere near the ThunderX-1 native latency - the FPGA is running at 300MHz and we use quite a bit of pipelining in our implementation.
Bandwidth is more interesting. 19 GiB/s is doing a pretty good job of using both links, each of which has a theoretical maximum bandwidth of just over 12 GiB/s.
Could we get near this? We doubt it in the general case: as we explain below, for the FPGA to max out both ECI links, you either need a hard partition of bandwidth between functions on the FPGA, or a lot of expensive coordination on the FPGA between the two links. We’ll report figures for Enzian on two links for different scenarios when we get them.
What’s actually going on in ECI?
Let’s unpack this a bit more, in terms of what it means for code someone might write on the FPGA. We should start with what ECI looks like at the lower layers, since it’s a bit complicated.
At the highest level, ECI is a fairly straightforward MOESI-based protocol that allows caching at both the home node and a remote node. Our paper xxx talks in more detail how we abstract the Cavium side of things to create ECI.
Each message over ECI is sent on one of 13 virtual circuits (VCs). The VC used is determined by the type of message (coherence request, response, I/O read, Inter-processor Interrupt, Barrier, etc.).
Below that, ECI runs over 24 10BaseKR lanes running at 10 GHz. This gives a theoretical maximum bandwidth of 30 GiB/s, but obviously this is unattainable in practice due to signaling overhead, etc.
However, these 24 lanes are divided into two different links of 12 lanes each. Each link carries its own set of 13 VCs.
How the CPU uses these links is configured when the board powers up. The default used by the Gigabyte server we benchmarked above is to use both links by load-balancing cache messages across both links based on how much room is available in the transmit FIFOs (other accesses, like uncached I/O requests, are always sent on one of the links).
We can do this on the FPGA, although it requires coordination across the two links (since requests for a given cache line / address can potentially come in on either link), which would introduce additional latency into our implementation.
Alternatively, we could configure the CPU to partition requests between the two links based on which part of the L2 cache maps to the address. We’ve not explored this, and it’s complex for a number of reasons. For one thing, it’s hard (and a bit inflexible) to map this to a real workload. Moreover, the mapping of physical address to cache set is something we don’t yet fully understand, and so some reverse-engineering is required there before we can map it well to a given workload.
For that reason, we are sticking to load-balancing across the two links based on the FIFO space and paying the price of coordination, which is not present in the micro-benchmark above.
Conclusion
ECI is perhaps not the protocol one would have designed from scratch for a hybrid CPU/FPGA system, but the functionality is pretty good, and we’re very happy with the performance. We get considerable control over where and how things are cached, as well as other functionality like IPIs and I/O byte-enabled requests.
Kudos to Abishek Ramdas, Adam Turowski, and all the other Enzian team members who helped to get us this far with ECI.