Subscribe to the mailing list for updates.
April 28, 2020
Adventures in Cache Coherence Interoperability
As we’ve said many times, a key feature of Enzian as a research computer is the low-level access to the cache coherency protocol, which in our case is the native inter-socket protocol implemented by the ThunderX-1 CPU.
Marvell (then Cavium) were wonderfully helpful in furnishing us with internal documentation, access to the engineers (themselves very helpful and encouraging), and even providing us with the two EBB88 evaluation boards. These boards have a single ThunderX-1 processor, but also 3 connectors which bring out the coherency protocol (8 lanes on each).
We built Enzian 2 by connecting each of these boards to a Xilinx VCU118 board (generously donated by Xilinx) via an adapter board that David Cock designed at ETH Zurich, and these two machines remain our main hardware platform until the new, single Enzian 3 boards are ready for system bringup.
A critical use of these boards is to implement ECI, the Enzian Coherence Interface, which is our implementation of the coherence protocol on the FPGA.
As anyone who has had to interoperate with a complex protocol by hand knows, the documentation is rarely quite enough to get things working
- even if the other implementation with which you are trying to interoperate is quite robust. This is the case with the ThunderX - not only is the protocol quite tolerant to timing variations and occasional bit errors, there are also a lot diagnostic features on the processor to help you figure out what is going wrong (including an on-board logic analyzer).
However, following the documentation and working by trial-and-error only got us so far with some annoying bugs in our work that were proving hard to fix. In the end, we decided we needed a set of reference traces of the protocol working correctly.
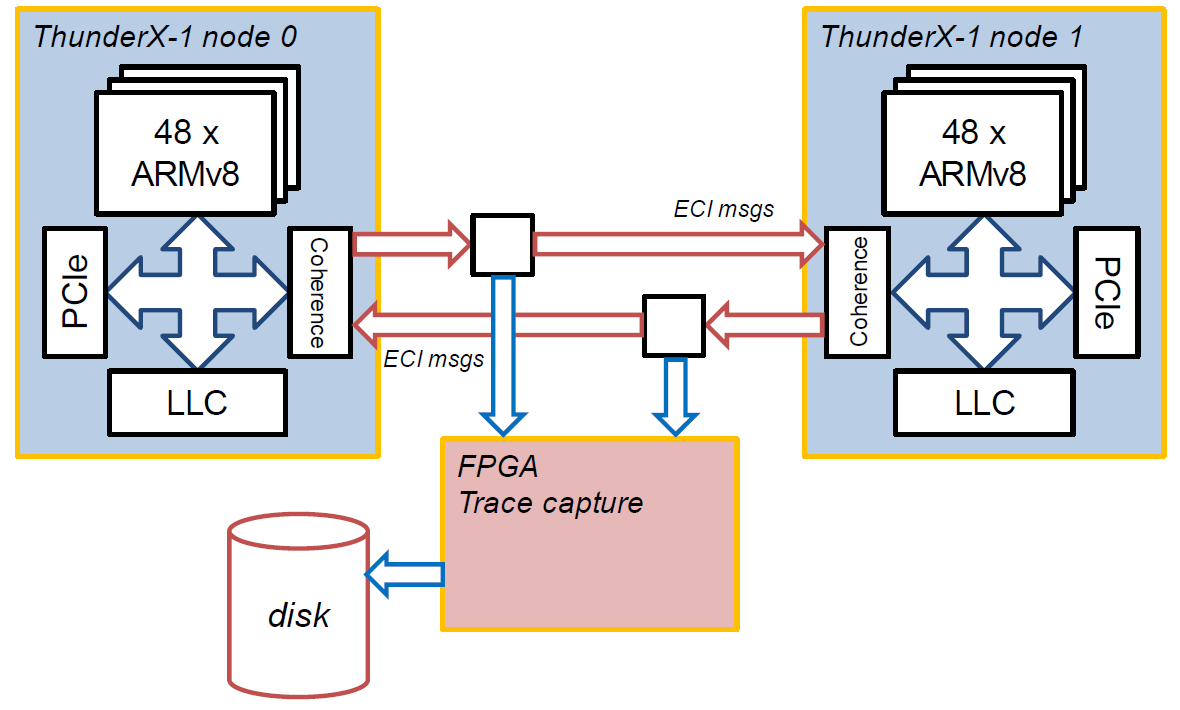
To this end, we rearranged the trolley which holds our two Enzian 2 prototypes. We connected 8 lanes of the coherence link from one EBB88 board right across to the other, via a passive tap which fed into one of the FPGA boards, like this:
This involved clipping this hardware to the side of the trolley:

Turning on both EBB88s causes them to boot as a single 2-socket NUMA system (which is a very cool hardware feature we’ve relied on a lot). We programmed the FPGA to capture all the coherence traffic it saw and dump it to disk, and we captured traces booting Linux, BSD, etc.
Now we needed to make sense of these traces, and this is where Jakob Meier came in. His Masters dissertation (Tools for Cache Coherence Protocol Interoperability, completed a few weeks ago) was about tools and techniques to analyze these traces and use them to help us debug our own FPGA implementation.
We had looked at such traces before, and had even written a WireShark plugin to parse them. We also had a working parser for the messages in Python, that also operated on traces in PCAP file format.
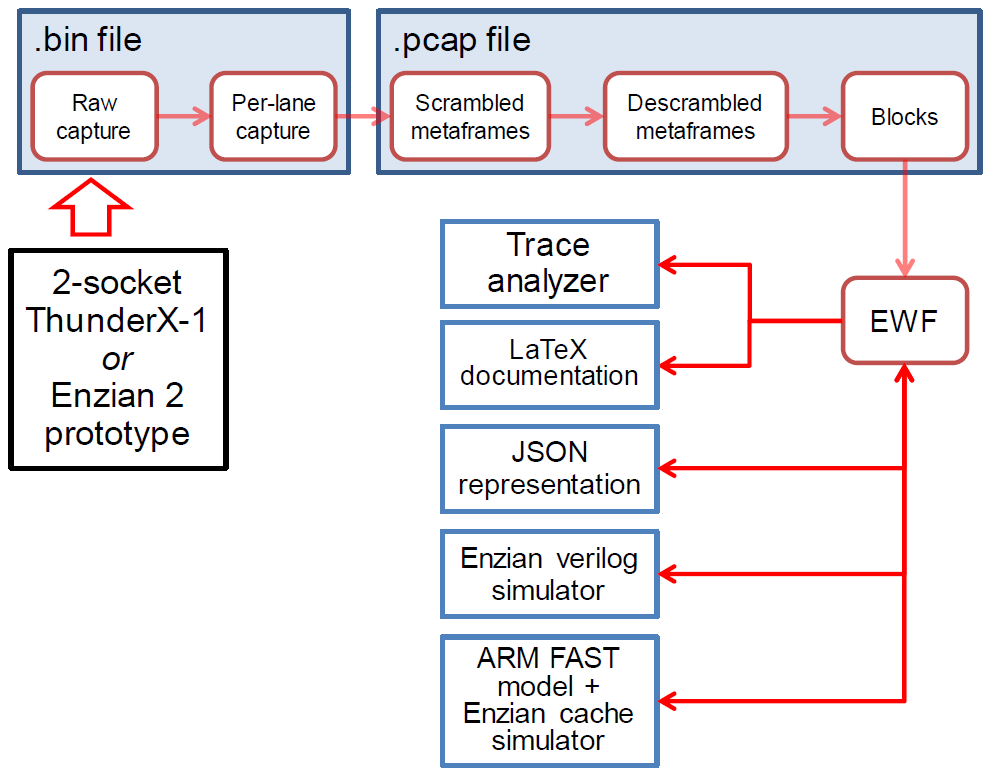
For this, more sustained effort, we decided to define our own representation of all the ECI message types, which we refer to as the ECI Wire Format, or EWF. It’s binary for space efficiency, but has a corresponding JSON representation that’s easier to read. This allows us to not only write multiple tools for looking at traces, but also use EWF as a standard format for other purposes (such as the Enzian simulation suite).
Generating an EWF file itself is non-trivial, since our trace is fairly low-level: we need to reconstruct high-level ECI messages across several layers of striping across lanes and multiplexing over logical links. As an aside, we decided to specify the binary format of data units at various layers in the stack using ARM’s ASL specification language, and generate encoding and decoding code from this specification. In the long run, we’d also like to check that our Verilog code conforms this specification as well, but right now that’s manual (and, yes, we occasionally make mistakes).
Most of Jacob’s thesis is around what you can do with a trace in EWF format, having converted a binary trace file to this layout. Some of the workflow looks like this:
The simplest application is basically querying a given trace: looking for the set of packets sent and received when a particular kind of event is observed, for example, or doing basic analytic queries of the trace (such as the number of sent vs. acked packets in each direction). An early sanity check that Jacob’s framework enabled was to check that we know the complete set of messages that we might encounter (it turned out we didn’t, but we do now).
Even these kinds of applications are non-trivial, as they require some kind of time synchronization between the two halves of the trace (one half in each direction). Moreover, there’s simply a lot of data in our traces. To get good performance (and because it’s cool), all this processing is done using Frank McSherry’s Timely Dataflow library, which we also used in the Systems Group as the basis of the Strymon stream processor.
Things get even more interesting once we try to understand ECI at the level of transactions, and ultimately high-level operations composed of many message exchanges. To do this, we have a specification based on state machines which is checked against the trace. If the everything in the trace can be explained by the list of transactions we have already specified, we probably have a good enough description of ECI to reliably talk to a ThunderX-1 running a typical workload under Linux or BSD.