Subscribe to the mailing list for updates.
April 19, 2020
Enzian and cache coherency
The role of cache coherency in Enzian is interesting to think about. Consider a typical two-socket NUMA machine (such as the kind of system that the ThunderX-1 processor was designed for):
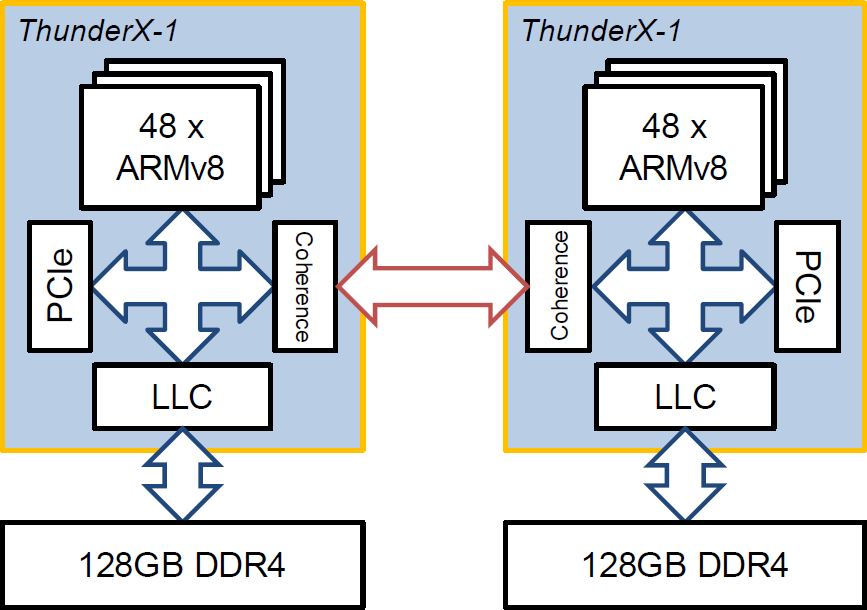
The Last-Level Cache (LLC) on a socket talks to its peer on the other socket via the coherency protocol to provide a single, coherent physical address space shared between the cores on both sockets.
The ThunderX-1’s coherency protocol is MOESI-based, with some a few interesting features (for example, when requesting a line from its home node, you can specify whether it should be cached at the home node or the requesting node). The protocol also handles all other communication between the two sockets: interrupts, I/O loads and stores, and non-cacheable memory accesses, among other things.
The way that most FPGA accelerators (and GPUs, etc.) work today is to connect to the PCIe root complex on one of the processor sockets. For example, if you were to plug one of the new datacenter FPGA accelerators from Xilinx into a single socket system, it might look a bit like this:
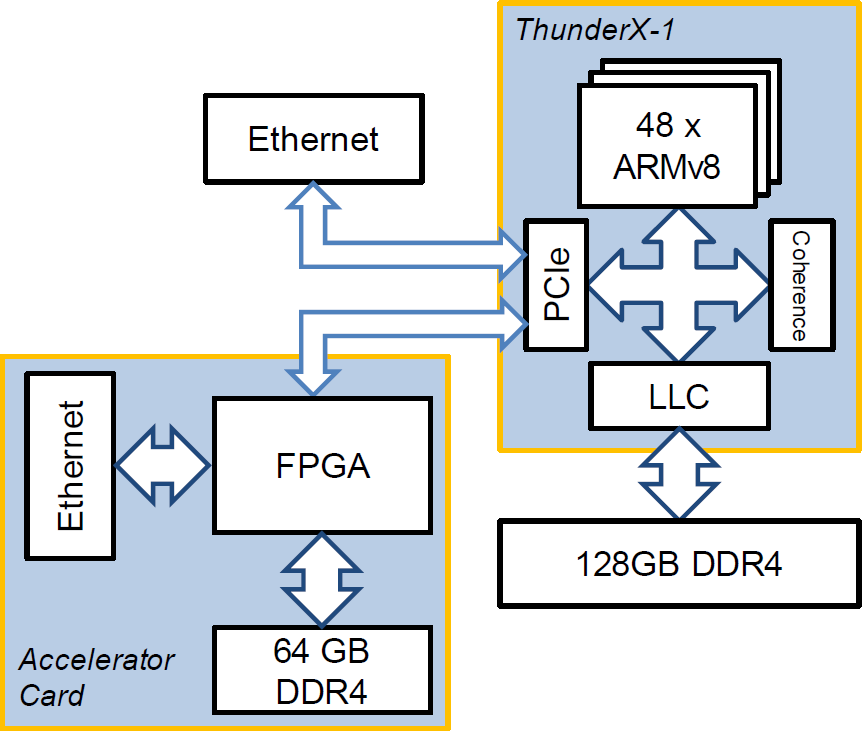
The FPGA here is very much an accelerator for the main CPU. It can do quite a lot over PCIe, depending on how the host OS sets things up, such as access host memory and copy data between its own RAM and the host machine’s. Modern FPGA cards even have quite a bit of memory, and considerable network bandwidth.
This makes perfect sense if what you want to do is accelerate particular applications. It follows the traditional GPU model, and works “out of the box” today: you just plug in the card, install the FPGA firmware and tools supplied by the vendor, and the rest of your computer continues working as normal. We work a lot with this kinds of cards (many of them generously donated by Xilinx and Intel, for which we are very grateful!).
From a research perspective, however, this is quite short-term. Given the capabilities of modern, large FPGAs, putting one on the far side of a peripheral bus is missing opportunities for many applications for FPGAs beyond simple acceleration.
One of the key features of Enzian is that we don’t (by default) do this. Enzian looks much like a NUMA system, with one socket holding the FPGA instead of a processor:
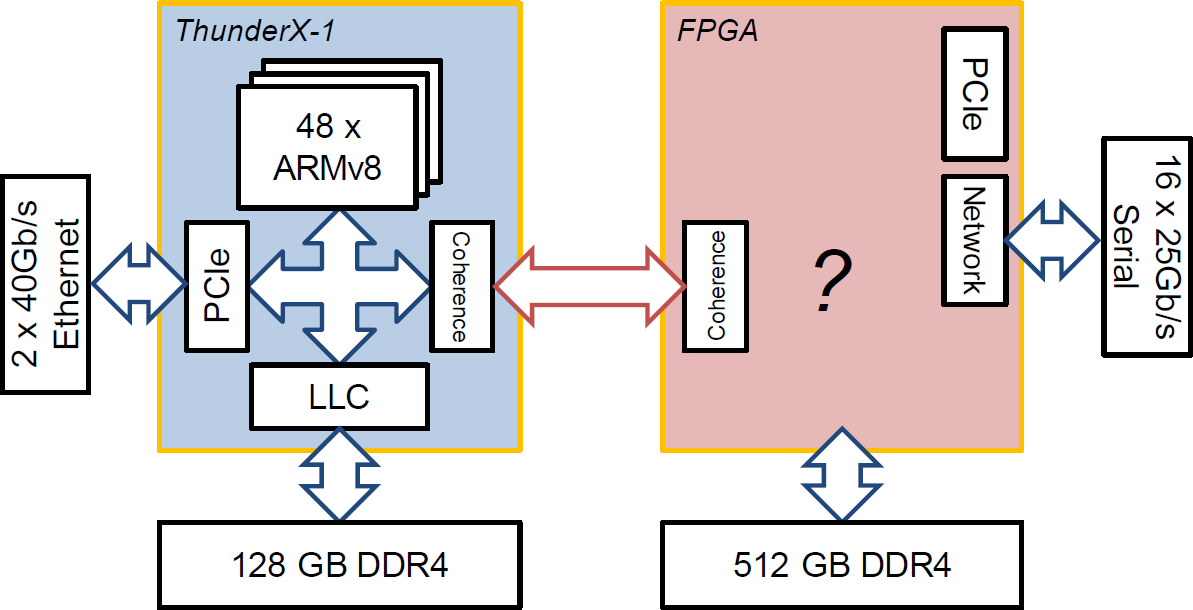
Exactly what goes in the box marked “?” in the FPGA on the “East Side” is a very interesting question, and we talk about it a lot in the Enzian group. It’s central to almost any research application for Enzian, whether it be accelerator interface design, custom memory controllers, distributed cache coherence, or (at least) dozen other use cases.
However, a basic requirement is that the CPU on the “West Side” should get confused about what is sitting on the other end of the coherence link - after all, the protocol is designed with the fundamental assumption that the only thing that it will encounter on that link is another, identical ThunderX-1.
The upshot is that a big part of Enzian development (other than building the hardware) is dedicated to implementing firmware on the FPGA that speaks the coherence protocol in a way that the CPU expects, but at the same time allows all kinds of unconventional uses of the protocol by FPGA applications and clever software on the CPU.
We had a lot of help from Marvell in the form of documentation, advice, questions answered by email, friendly vibes, etc., but this has still been something of a challenge.
Cache coherence protocols are not built with interoperability in mind, for good reasons, and often the key reference for how they work is the implementation itself - indeed, there is rarely any distinction made between the protocol itself and the implementation. This is in contrast to the situation with Internet protocols, for example, where the protocol is defined independently of any implementation.
We may be one of the first groups to try inter-operating with an existing, proprietary cache coherence protocol that was not designed with this in mind. For this reason, we refer to the protocol we implement in Enzian as ECI (the Enzian Coherent Interconnect). ECI is designed to interoperate with an instance of CCPI (the Cavium Cache Coherent Interface).
On the positive side, all this has caused us to develop a bunch of tools that will help a lot with application development on Enzian: simulators, ECI protocol specifications, trace analysis and debugging tools, etc. which we’ll release with the hardware as soon as it’s ready. We’ll post some more information about these over the next few weeks, and we’d like to write a paper on our experiences implementing and debugging ECI (though it’s not clear where we would publish it…).